word2vec
What is word2vec?
- Word2vec is an approach to create word embeddings.
- Word embedding is a representation of a word as a numeric vector.
- Except for word2vec there exist other methods to create word embeddings, such as fastText, GloVe, ELMO, BERT, GPT-2, etc.
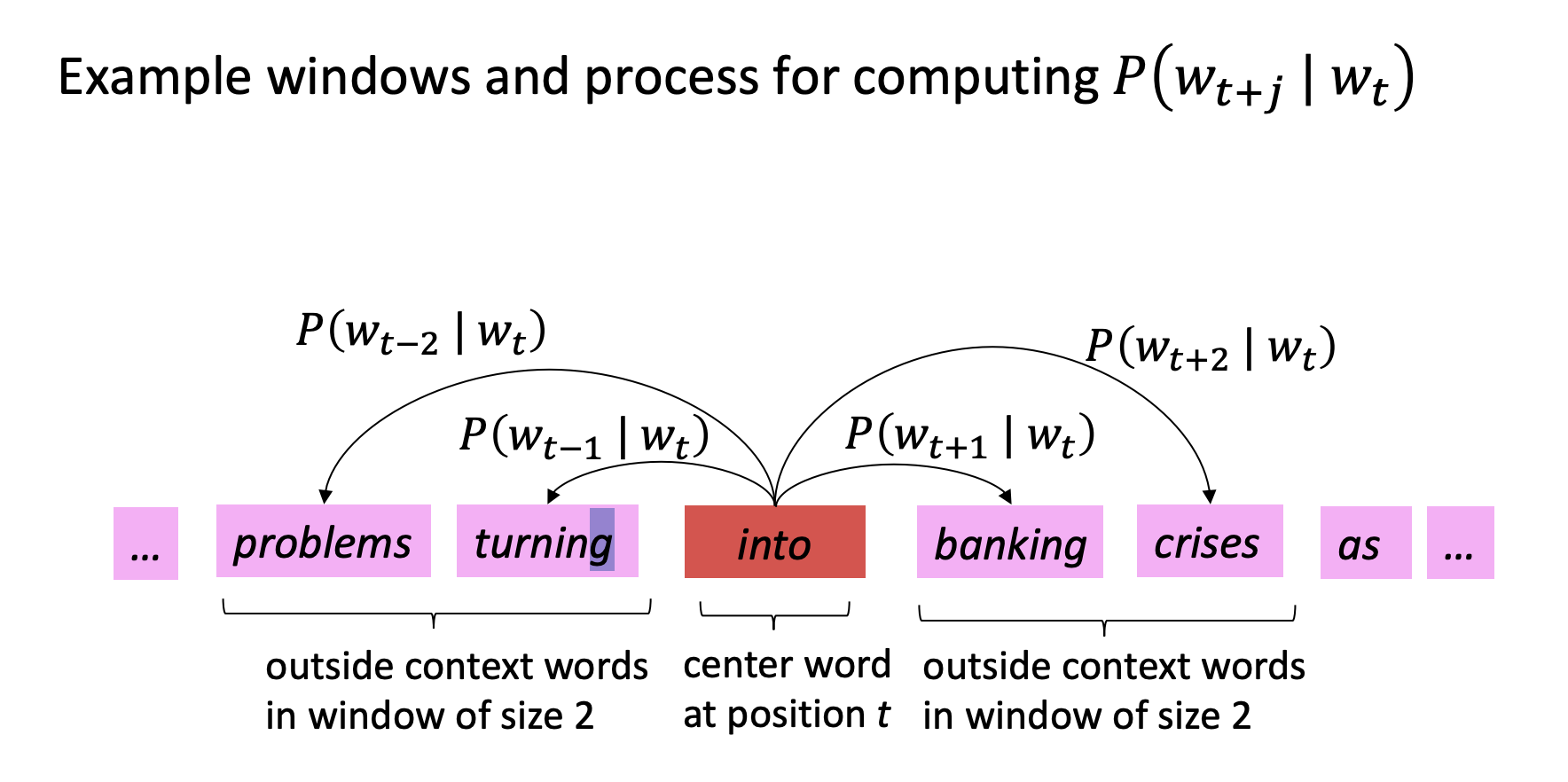
Image: Word2Vec Overview. Source: Stanford CS224N Notes
Model Architecture
Word2vec is based on the idea that a word’s meaning is defined by its context. Context is represented as surrounding words.
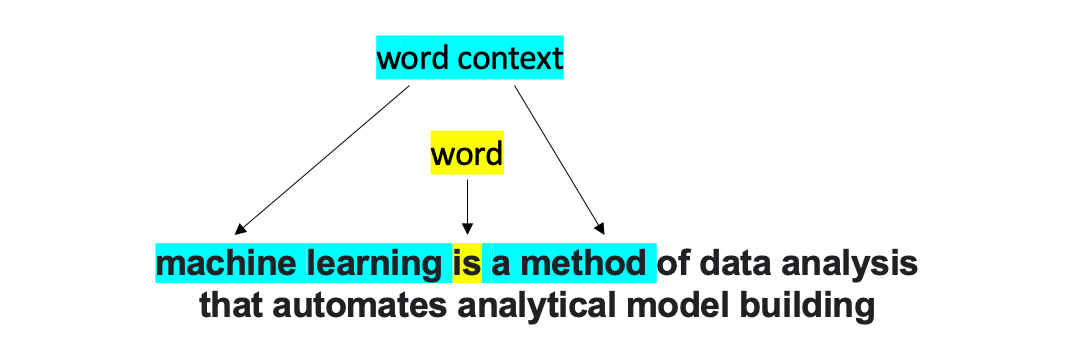
Image: A word and its context. Image by Author
There are two word2vec architectures proposed in the paper:
- CBOW (Continuous Bag-of-Words) – a model that predicts a current word based on its context words.
- Skip-Gram – a model that predicts context words based on the current word.
Both CBOW and Skip-Gram models are multi-class classification models by definition.
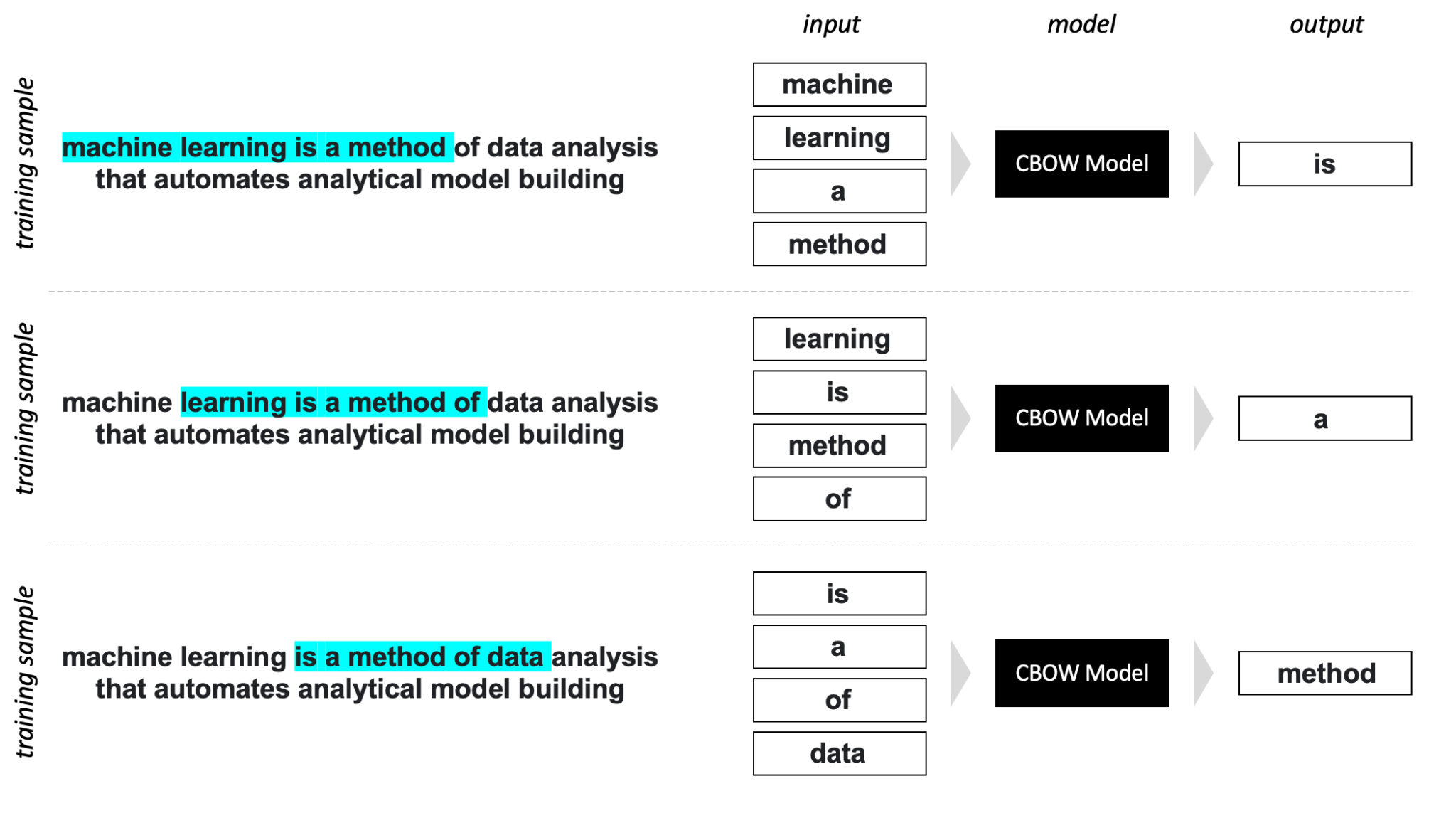
Image: CBOW Model: High-level Overview.
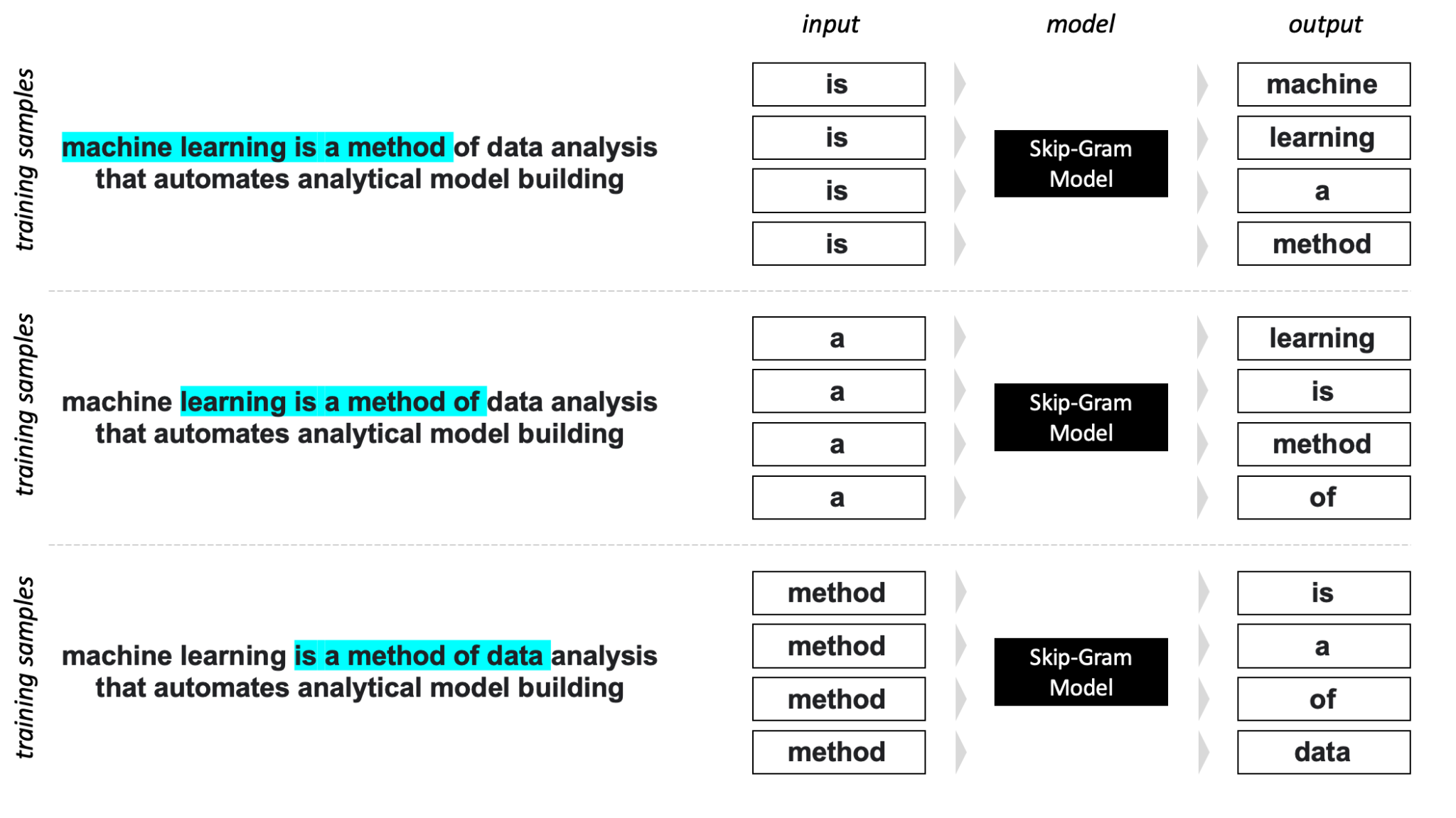
Image: Skip-Gram Model: High-level Overview.
Word2vec model is very simple and has only two layers:
- Embedding layer, which takes word ID and returns its 300-dimensional vector.
- Then comes the Linear (Dense) layer with a Softmax activation. We create a model for a multi-class classification task, where the number of classes is equal to the number of words in the vocabulary.
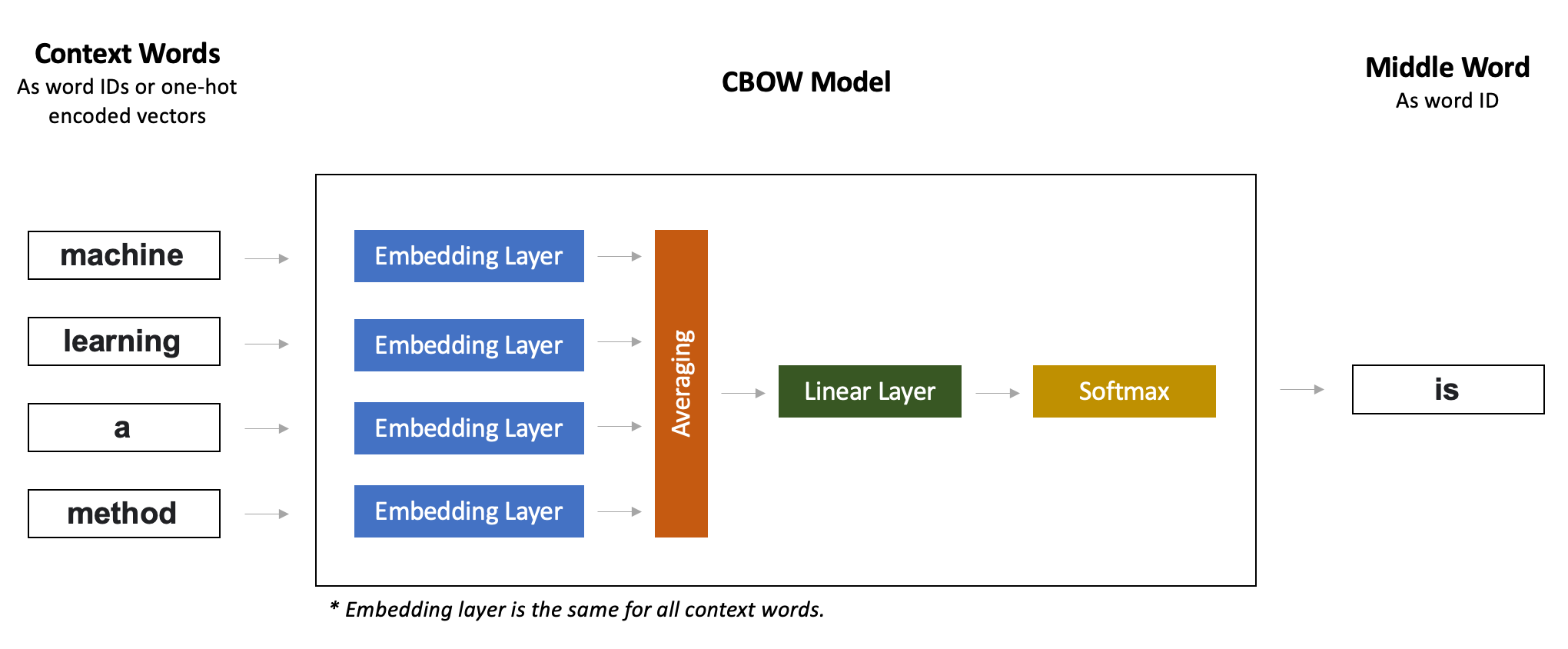
Image: CBOW Model: Architecture in Details.
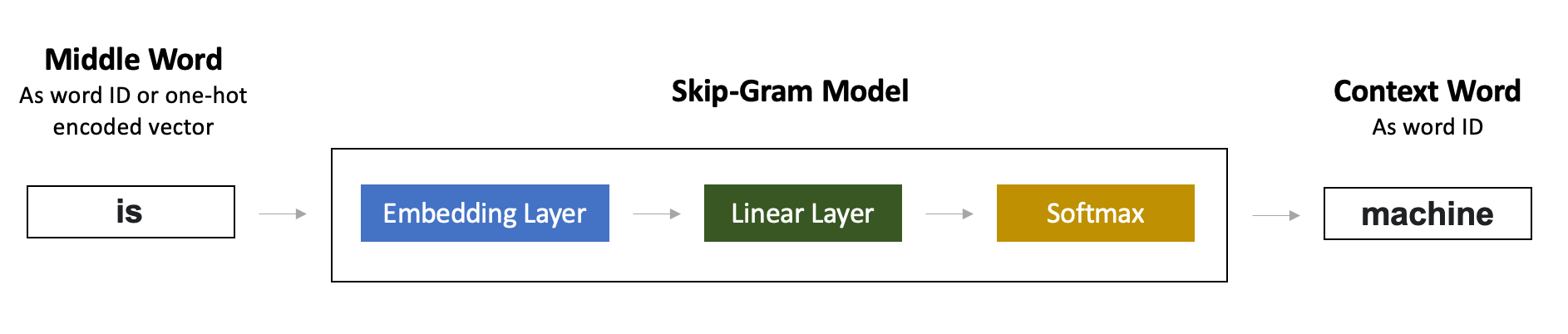
Image: Skip-Gram Model: Architecture in Details.
Data Preparation
It is better to create vocabulary:
- Either by filtering out rare words, that occurred less than N times in the corpus;
- Or by choosing the top N most frequent words.
Vocabulary is usually represented as a dictionary data structure:
vocab = {
"a": 1,
"analysis": 2,
"analytical": 3,
"automates": 4,
"building": 5,
"data": 6,
...
}
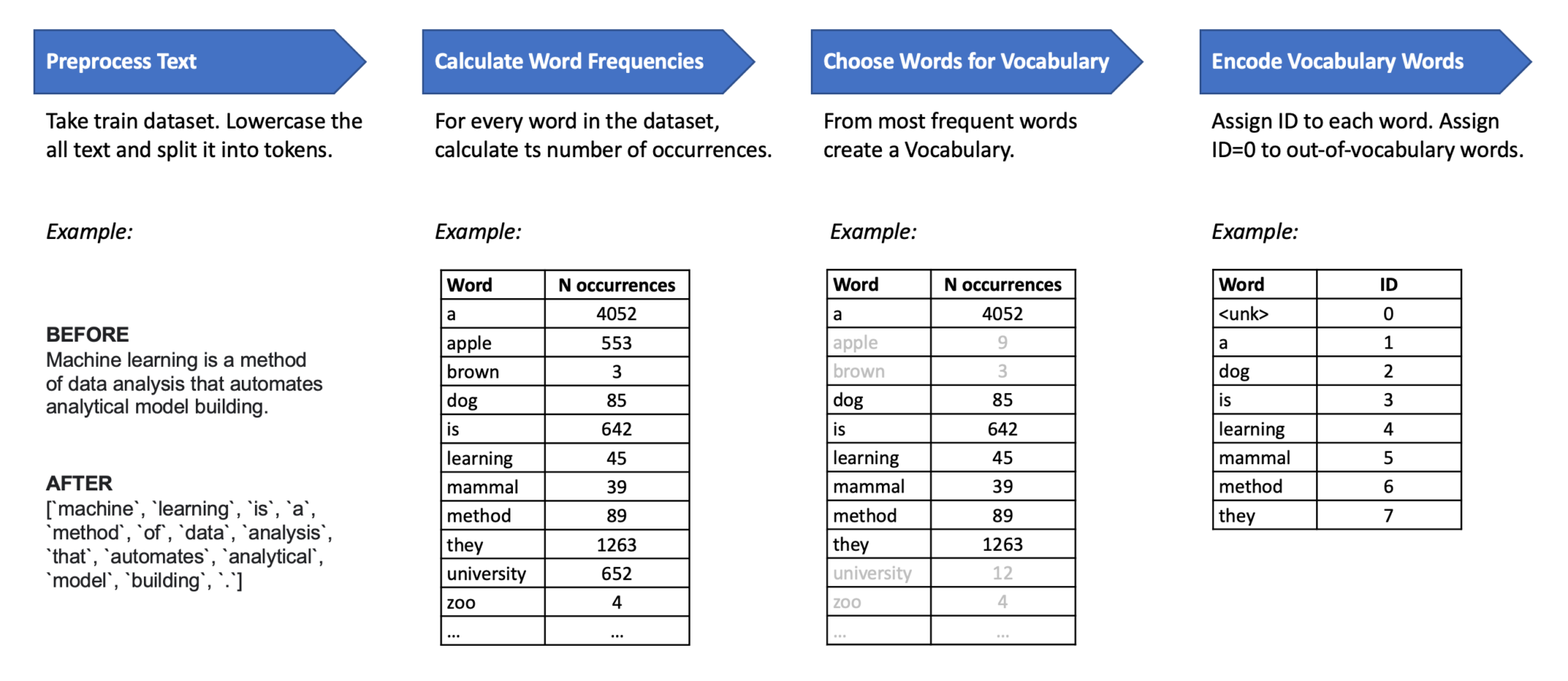
Image: How to create Vocabulary from a text corpus.
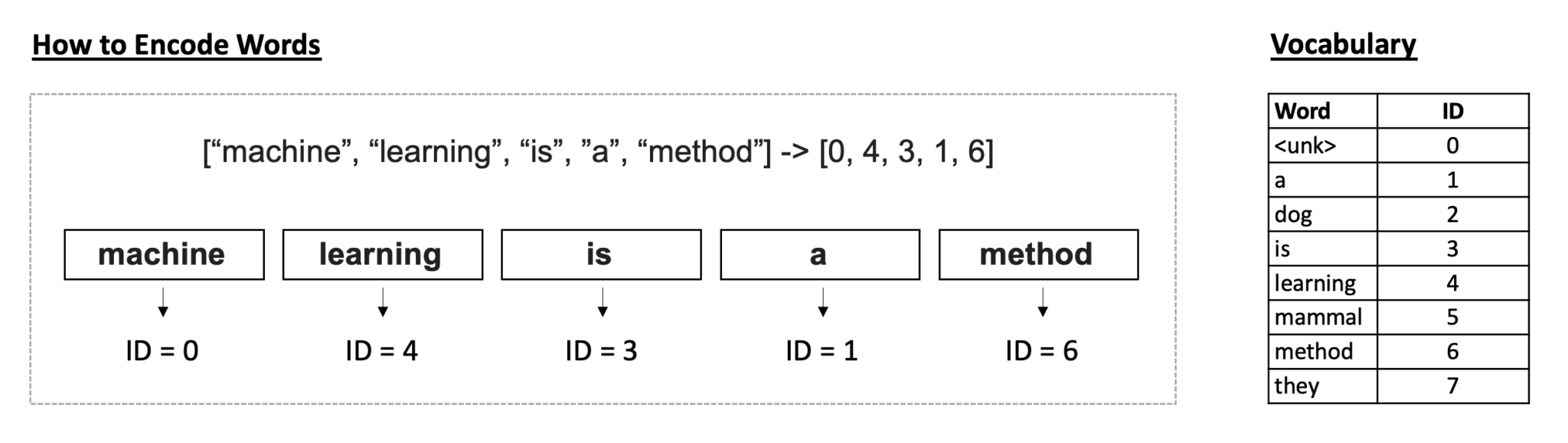
Image: How to Encode words with Vocabulary IDs.
Objective Function
For each position
The objective function is the average negative log likelihood:
Minimizing objective function
For a center word
Training Details
Word2vec is trained as a multi-class classification model using Cross-Entropy loss.
TODO: add details on the dataset prep, optimizer choice, ...
Notes:
- build_vocab_from_iterator
- max_embed_norm
- expect a batch of inputs in the
forwardmethod.
References
- Word2vec with PyTorch: Implementing the Original Paper - towardsdatascience
- Efficient Estimation of Word Representations in Vector Space - arxiv
- Distributed Representations of Words and Phrases and their Compositionality
- Distributed Representations of Sentences and Documents
- Enriching Word Vectors with Subword Information
- The Illustrated Word2vec
- An introduction to word embeddings for text analysis