Stable Diffusion
Stable Diffusion Pipeline
the highest-quality open source text to image model as of late 2022.
The AutoEncoder
The AE can 'encode' an image into some sort of latent representation, and decode this back into an image.
Why do we even use an autoencoder?
We can do diffusion in pixel space - where the model gets all the image data as inputs and produces an output prediction of the same shape. But this means processing a LOT of data, and make high-resolution generation very computationally expensive.
Some solutions to this involve doing diffusion at low resolution (64px for eg) and then training a separate model to upscale repeatedly (as with D2/Imagen). But latent diffusion instead does the diffusion process in this 'latent space', using the compressed representations from our AE rather than raw images.
The Scheduler
During training, we add some noise to an image an then have the model try to predict the noise. If we always added a ton of noise, the model might not have much to work with. If we only add a tiny amount, the model won't be able to do much with the random starting points we use for sampling. So during training the amount is varied, according to some distribution.
During sampling, we want to 'denoise' over a number of steps. How many steps and how much noise we should aim for at each step are going to affect the final result. 'sigma' is the amount of noise added to the latent representation.
Other diffusion models may be trained with different noising and scheduling approaches, some of which keep the variance fairly constant across noise levels ('variance preserving') with different scaling and mixing tricks instead of having noisy latents with higher and higher variance as more noise is added ('variance exploding').
If we want to start from random noise instead of a noised image, we need to scale it by the largest sigma value used during training, ~14 in this case. And before these noisy latents are fed to the model they are scaled again in the so-called pre-conditioning step:
Classifier-Free Guidance
Classifier-Free Guidance is a method to increase the adherence of the output to the conditioning signal we used (the text).
Roughly speaking, the larger the guidance the more the model tries to represent the text prompt.
Negative prompts
Negative prompting refers to the use of another prompt (instead of a completely unconditioned generation), and scaling the difference between generations of that prompt and the conditioned generation.
By using the negative prompt we move more towards the direction of the positive prompt, effectively reducing the importance of the negative prompt in our composition.
Image to Image
Even though Stable Diffusion was trained to generate images, and optionally drive the generation using text conditioning, we can use the raw image diffusion process for other tasks.
For example, instead of starting from pure noise, we can start from an image an add a certain amount of noise to it. We are replacing the initial steps of the denoising and pretending our image is what the algorithm came up with. Then we continue the diffusion process from that state as usual.
Textual Inversion
Textual inversion is a process where you can quickly "teach" a new word to the text model and train its embeddings close to some visual representation. This is achieved by adding a new token to the vocabulary, freezing the weights of all the models (except the text encoder), and train with a few representative images.
Dreambooth
Dreambooth is a kind of fine-tuning that attempts to introduce new subjects by providing just a few images of the new subject. The goal is similar to that of Textual Inversion, but the process is different. Instead of creating a new token as Textual Inversion does, we select an existing token in the vocabulary (usually a rarely used one), and fine-tune the model for a few hundred steps to bring that token close to the images we provide. This is a regular fine-tuning process in which all modules are unfrozen.
Fine-tuning with Dreambooth is finicky and sensitive to hyperparameters, as we are essentially asking the model to overfit the prompt to the supplied images. In some situations we observe problems such as catastrophic forgetting of the associated term ("person" in this case). The authors applied a technique called "prior preservation" to try to avoid it by performing a special regularization using other examples of the term, in addition to the ones we provided. The cool thing about this idea is that those examples can be easily generated by the pre-trained Stable Diffusion model itself! We did not use that method in the model we trained for the previous example.
Other ideas that may work include: use EMA so that the final weights preserve some of the previous knowledge, use progressive learning rates for fine-tuning, or combine the best of Textual Inversion with Dreambooth. These could make for some interesting projects to try out!
What is Stable Diffusion
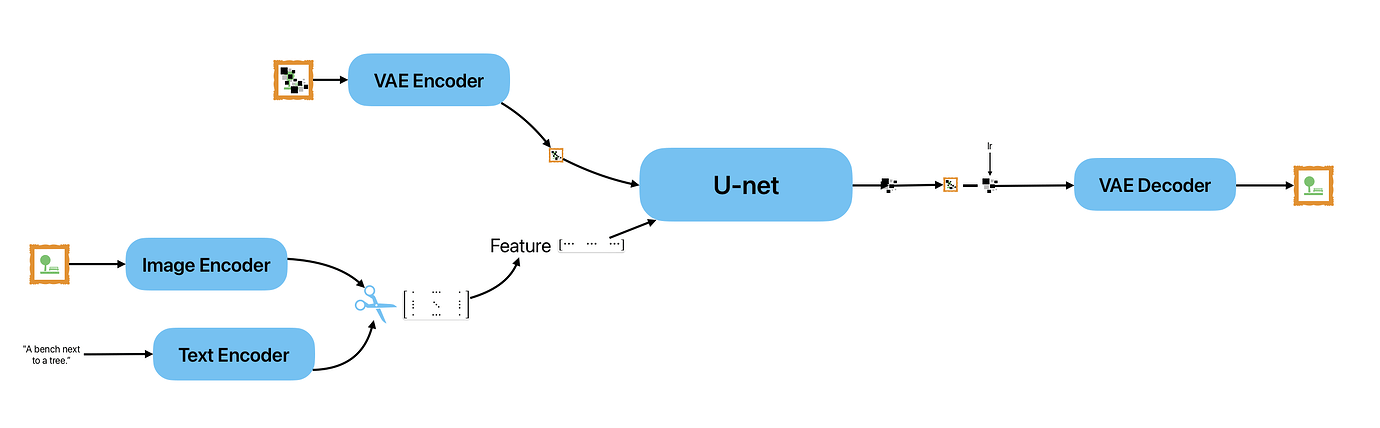
There are three main components in latent diffusion.
- An autoencoder (VAE).
- A U-Net.
- A text-encoder, e.g. CLIP's Text Encoder.
The output of the U-Net, being the noise residual, is used to compute a denoised latent image representation via a scheduler algorithm. Many different scheduler algorithms can be used for this computation, each having its pros and cons.
For Stable Diffusion, we recommend using one of:
- PNDM scheduler (used by default)
- DDIM scheduler
- K-LMS scheduler
Latents and callbacks
Stable Diffusion is based on a particular type of diffusion model called Latent Diffusion, proposed in High-Resolution Image Synthesis with Latent Diffusion Models.
General diffusion models are machine learning systems that are trained to denoise random gaussian noise step by step, to get to a sample of interest, such as an image. For a more detailed overview of how they work, check this colab.
Diffusion models have shown to achieve state-of-the-art results for generating image data. But one downside of diffusion models is that the reverse denoising process is slow. In addition, these models consume a lot of memory because they operate in pixel space, which becomes unreasonably expensive when generating high-resolution images. Therefore, it is challenging to train these models and also use them for inference.
Latent diffusion can reduce the memory and compute complexity by applying the diffusion process over a lower dimensional latent space, instead of using the actual pixel space. This is the key difference between standard diffusion and latent diffusion models: in latent diffusion the model is trained to generate latent (compressed) representations of the images.
Reference
-
How to fine tune stable diffusion: how we made the text-to-pokemon model at Lambda
-
[An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion](https://textual-inversion.github.io/
Further Readings:
Projects:
- https://textual-inversion.github.io/
- https://dreambooth.github.io/
- https://github.com/leejet/stable-diffusion.cpp/tree/master
Extra Resources:
- https://erdem.pl/2023/11/step-by-step-visual-introduction-to-diffusion-models
- https://sander.ai/2022/05/26/guidance.html
Related work:
Course Notes:
sd_lecture_9_summary
sd_lecture_10_summary
sd_lecture_11_summary
sd_lecture_12_summary
sd_lecture_13_summary
sd_lecture_14_summary
sd_lecture_15_summary
sd_lecture_16_summary
sd_lecture_17_summary
sd_lecture_18_summary
sd_lecture_19_summary
sd_lecture_20_summary
sd_lecture_21_summary
sd_lecture_22_summary
sd_lecture_23_summary
sd_lecture_24_summary
sd_lecture_25_summary
fast.ai course:
-
- [ ]